



Inferences
Introduction
Our Serverless Inference products provide easy access to powerful models across different domains. With just an API key and endpoint, you can start running inference without worrying about the underlying infrastructure, scaling, or deployment.
Overview
Here is an overview of our Serverless Inference products:
LLM Inference
LLM Inference gives you access to large language models for a wide range of text-based tasks. Whether you need to build chatbots, summarize documents, generate structured output, or perform custom NLP operations, LLM Inference provides a reliable and scalable way to integrate language models into your applications and workflows.
Vision (VLM)
Vision Inference enables multimodal capabilities by combining language and vision understanding. Use Vision to analyze images with natural language queries, describe visual content, or perform multimodal reasoning where both text and images are inputs. This is particularly useful for captioning, classification, and multimodal chat applications.
Embedding
Embedding Inference lets you generate high-quality vector embeddings for text or other data. These embeddings can then be used for semantic search, clustering, retrieval-augmented generation (RAG), recommendation systems, and more. By leveraging embeddings, you can create meaningful representations of data for downstream applications and tasks.
Reranking
Reranking Inference improves the quality of search and retrieval pipelines by reordering candidate results based on semantic relevance. Given an initial list of results and a query, the reranker ensures that the most contextually relevant results surface to the top, improving user experience and retrieval accuracy.
Moderation
Moderation Inference helps you detect, classify, and manage unsafe or undesired content across text-based inputs and outputs. It enables applications to automatically identify categories such as harmful language, abuse, policy violations, or sensitive content before it reaches users or downstream systems. By integrating moderation directly into your AI workflows, you can enforce safety standards, comply with governance requirements, and build trustworthy AI experiences without manual review overhead.
Audio (Speech-to-Text)
Audio Inference provides speech-to-text capabilities that convert spoken audio into accurate, structured text. This enables applications to process voice inputs for transcription, analysis, and downstream language understanding tasks. Speech-to-text can be combined with other inference products, such as LLM Inference, Embedding, or Moderation, to build voice-enabled assistants, meeting transcription services, call analytics, or multimodal agent experiences where spoken input becomes actionable data.
Getting Started: Creating an API Key
The process of creating an API key is the same for all of our Serverless Inference products. In this example, we’ll walk through the steps for LLM Inference.
Step 1: Open the Product Page
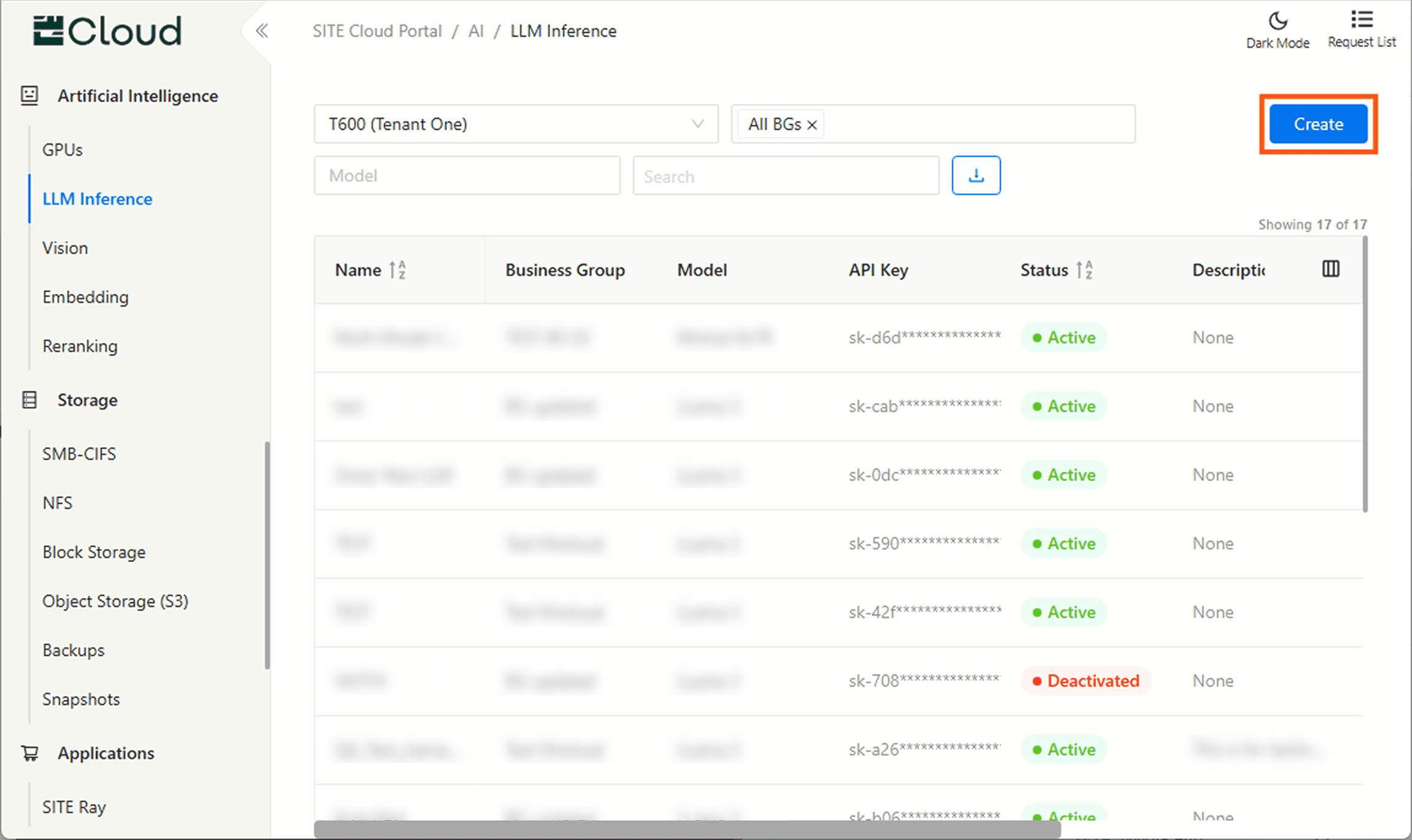
In the Cloud Portal, navigate to the product you want to use (here we’ve selected LLM Inference) to view and
manage your API keys, then click Create to open the creation modal
Step 2: Start Creating a New API Key

Now, select the model you’d like to use from the available list.
Step 3: Provide Key Details
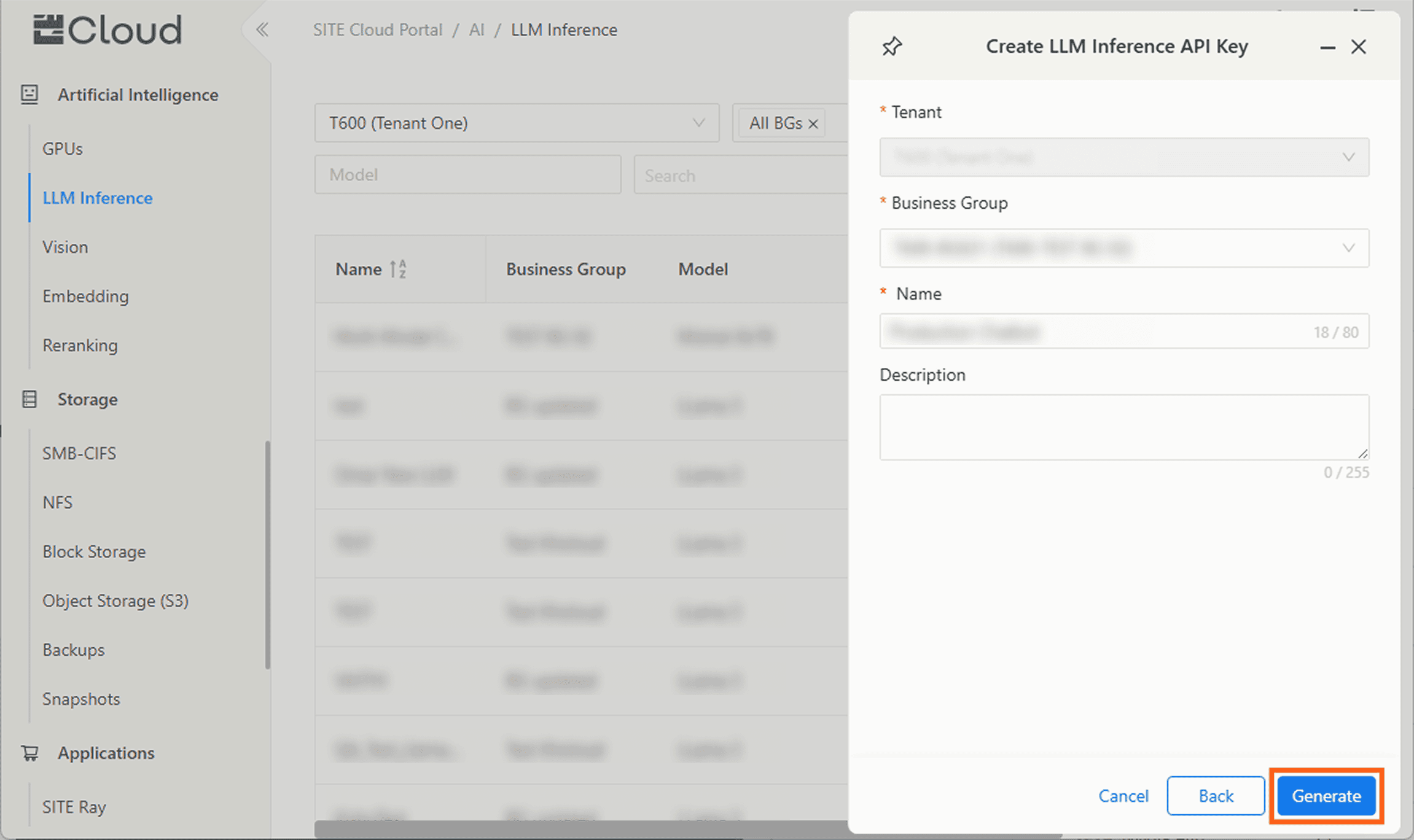
Fill in the required details, and an optional description.
Step 4: Copy Your Key and Endpoint
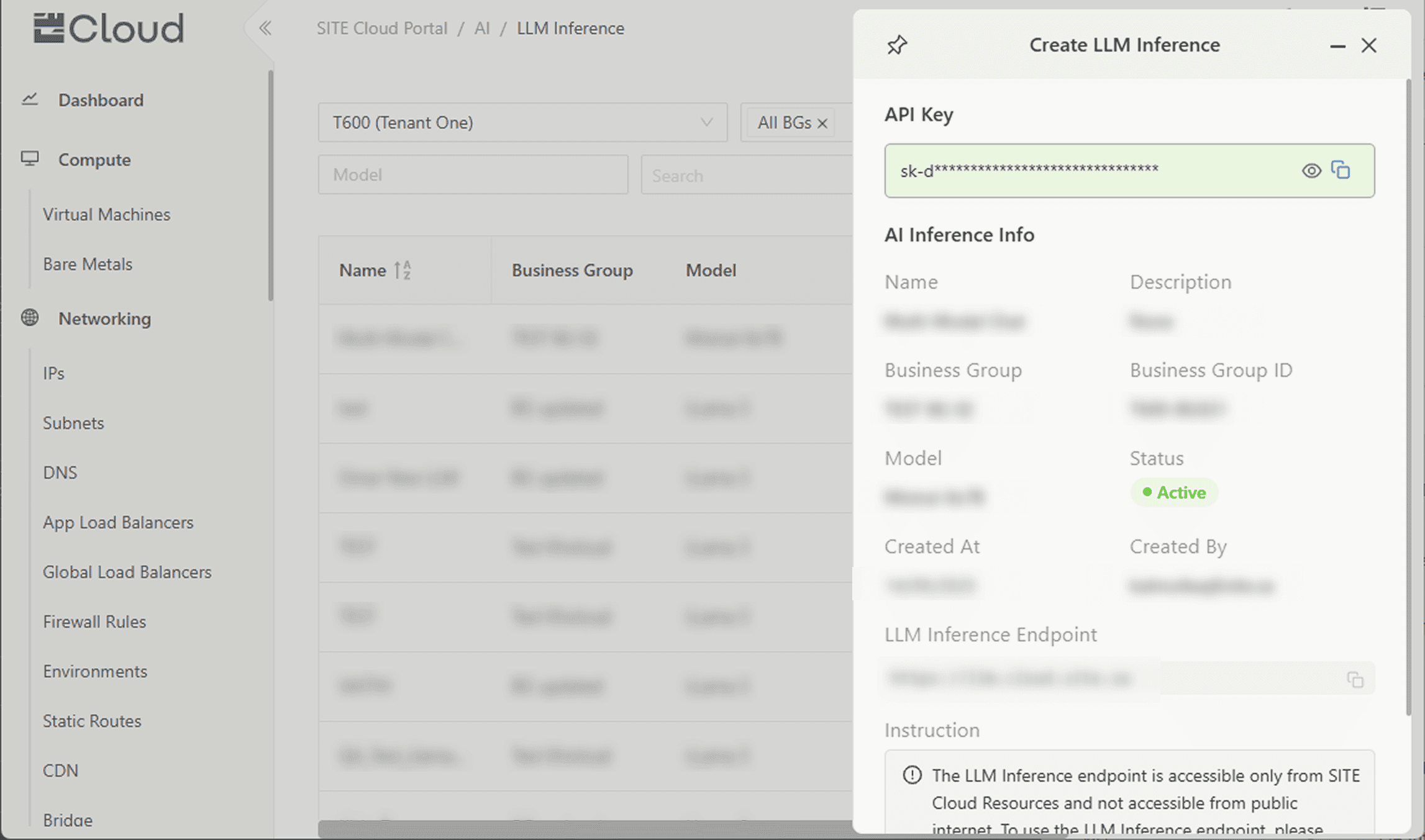
You’re all set! Your API key and Endpoint are ready. You can now begin making requests to your chosen Serverless Inference product.